近日,一个名不见经传的公司说要开源写了三年的时序物联网平台,这本来也不是什么新奇的事儿;但当看到该数据平台官网的性能测试报告的时候就有点不淡定了
1 | what's ... your problem |
随后创始人通过微信公众号比Hadoop快至少10倍的物联网大数据平台,我把它开源了和10余万行C代码开源之后,我被震惊了。。。,试图从不同角度来解释这个性能报告,但是群众看了之后还是接受不了性能会如此的好
坦白讲,看了这个性能测试报告,我也是不相信的,性能真的已经好到这个程度了吗?
当看到github上面的代码之后,尤其是短时间内集聚的这么多star,我决定探究一下tdengine,尝试理解一下他为什么如此之快。

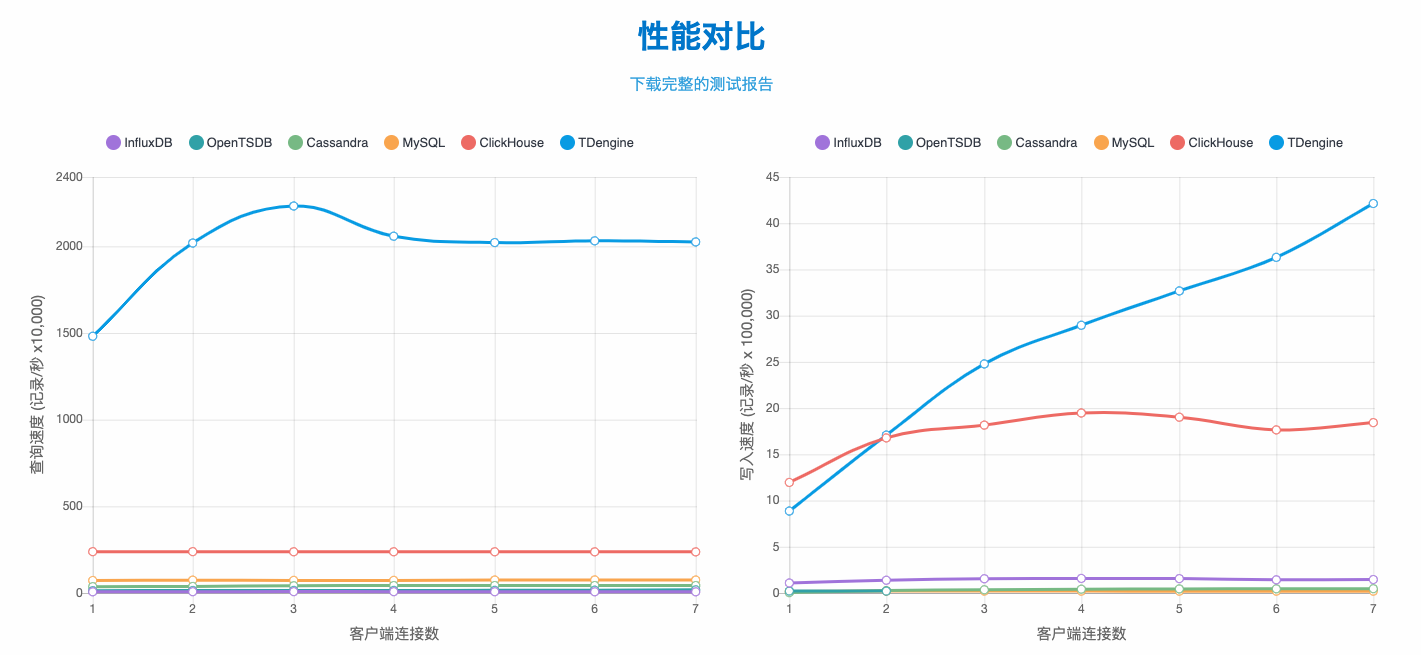
性能报告

对比influxdb的性能优势是:
- 写入性能5倍
- 读取性能35倍
- 聚合函数性能140倍
- 标签分组性能250倍
- 时间分组12倍
- 压缩1.8倍
下面尝试从其文档中找到性能优势的原因
数据模型
时序数据库有不同数据模型,有一种分类方式是这样的;
根据上面这种分类方法,tdengine属于窄表多列,并且有如下特点:
- 一个时序序列一张表
- 如果序列有多组采集量,每一组的采集频次是不一样的,需要对同一个序列建多张表
- 需要预先定义schema
- 有超级表的概念(具体看下文解释)
超级表 和 普通表
tdengine的超级表和普通表概念类似influxdb的measurement和series;
熟悉influxdb数据模型的同学知道,一个measurement包含多个序列,一个序列由series key确定,这里的series key是由measurements name + tag set 唯一确定,每个series真正存储数据值的部分叫fields;
tdengine的超级表和普通表正是对应了influxdb的measurement和fields;
其对应关系如下:
1 | 超级表 等于 measurements |
就时序数据库来讲,对高维序列的索引是逃不开的一件事,通常大家为了快,会选择把对序列的索引放到内存中,正如早期influxdb的做法,tdengine本质上也是这种做法;
但是这么做会导致内存的无限膨胀,终有一天会撑不住,除非能保证序列的维度被控制在有限的个数内,然而这一假设在机器监控场景是不现实的,单拿podid作为一个维度就足够喝一壶了;
所以后来influxdb做了倒排索引,并存储在磁盘上;
在tdengine的数据模型中,有一个值得注意的点:1
2. 如果序列有多组采集量,每一组的采集频次是不一样的,需要对同一个序列建多张表
这个点可以大大减少存储空间的消耗,使得存储数据的时候,所有的列只需要共用一个时间戳序列,比如1
cpu load5=123, load10=456 <Timstamp>
load5和load10只需要共用一个时间戳,influxdb因为没有这个假设,所以数据在按列存储的时候每个值都需要附带一个64位int的时间戳,使得存储空间基本两倍于tdengine。
存储模型
虚拟节点(vnode)
vnode是虚拟节点的简称,一个物理数据节点被虚拟成多个虚拟节点
- 每个虚拟节点有各自独享的缓冲、磁盘等资源
- 不同vnode之间资源隔离
- 一个表只能存到一个vnode中
- 一个vnode只能属于一个数据库
- 一个数据库可以包含一个到多个vnode
数据文件的组织方式
在一个vnode中,所有表在同一个时间范围内的数据是存到同一个文件组中的,比如v0f1804*文件存储了若干个表的某个时间段的数据。
一个vnode有一个元数据文件,其中存储了这个vnode的相关元数据;
1 | /var/lib/taos/ |
在数据文件中,数据是按照数据块存储的,每个数据块只包含一张表的数据;
每张表的数据是按列存储的,从而使得达到最大的压缩效果。
每一个文件组都由三个文件:head,data,last,这三个文件的作用如下
- head文件存储data文件数据块的索引信息,可以通过head文件迅速找到每个表的偏移量,结构如下
1
2
3
4
5
6
7
8
9
10
11<文件开始>
[文件头]
[表1偏移量]
[表2偏移量]
...
[表N偏移量]
[表1数据索引]
[表2数据索引]
...
[表N数据索引]
<文件结尾>
其中数据索引的结构如下:1
2
3
4
5
6
[索引块信息]
[数据块1索引]
[数据块2索引]
...
[数据块N索引]
数据块索引中记录了数据块存放的文件名称,数据块起始地址偏移量等信息
- data文件,即数据文件
存放了真实的数据,格式如下1
2
3
4
5
6
7<文件开始>
[文件头]
[数据块1]
[数据块2]
...
[数据块N]
<文件结尾>
其中数据块格式为1
2
3
4
5
6
7
8[列1信息]
[列2信息]
...
[列N信息]
[列1数据]
[列2数据]
...
[列N数据]
针对一个具体的查询语句,其流程是这样的
- 首先从meterObj文件拿到查询涉及的表的信息(具体是哪个head文件)
- 从head文件中拿到对应表的索引信息
- 从data文件中拿到对应的列的索引信息,并根据数据块的位置读取数据
需要注意的是,数据块中不仅记录原始信息,还会记录该数据块中数据的各种统计值,比如最大值、最小值,sum,count等。
以上就是数据存储的设计,可以看到这种设计中包含了一些重要的假设:
- 两个相邻数据点之间的时间间隔是固定的
- 数据是不能缺失的,必须按序写入
这两个假设会有使用场景上的限制,比如针对第二个假设,某些延迟的数据是无法写入系统的;
虽然有一些场景上的限制,但是这两个假设却能带来巨大的性能提升
- 存储空间的大大节省
- CPU使用率得到大大减少,写入不必再进行compact,也不必再进行排序
第一个好处的原因在于,数据等时间间隔(也就是一个等差数列),使得时间戳的存储可以借助于delta of delta,无论多长的时间戳序列只需要记录一个初始值加上一个delta就可以了,这种方式使得时间戳的存储空间成百上千倍倍的减少。
之前在对influxdb写入进行profilling的时候曾发现,compact过程和排序过程大概能占用写入CPU的20%左右,如果连带上compact和排序引起的gc,这一比例会更高。
除此之外,数据块中记录的统计值是造成聚合查询性能140倍的重要原因。
查询处理

以上是tdengine的查询过程,主要包括三个步骤
- client App解析sql语句,然后从管理节点拿到对应表的数据所在的节点
- client App发出请求到这些数据节点,然后数据节点根据请求吐出数据到client App
- client App根据返回的数据进行数据的合并
可以看到上述过程client App作用巨大,尤其是最后的数据合并操作对某些聚合函数(求中位数,求标准差等)是一个非常耗费内存和CPU的操作,这部分操作转到一个客户机上确实会大大减少数据存储节点的计算压力,也不失为一种好方法,关键还是要看客户买不买账。
REST查询方式

可能是为了减少用户的使用成本和增加用户使用的便利性,tdengine提供了REST的查询方式,上图即为REST查询方式的流程图。
这种查询方式将普通查询处理流程中本来由client App处理的过程转移到了数据节点中,所以数据节点其实即负责读又负责写。
所以压测报告中到底是使用的哪种查询方式呢?要知道InfluxDB和其他一些时序数据库并没有将数据合并这种重操作都转移到客户端来进行操作的。
集群设计
tdengine在集群设计上,除了之前提到的虚拟节点(vnode)和管理节点,还有虚拟节点组(vnode group)的概念,用来支持数据副本的概念,每个vnode group包含若干分布在不同机器上的vnode,vnode之间互为备份。
在数据分区上,tdengine认为单个表的数据只能存储在一个vnode上,并且是按照时间区间分别存储在不同的数据块上,这就已经够了,因为即使一个设备一秒发出16Bytes的数据,一年产生的数据也不到0.5G,一个vnode完全能够处理;简言之tdengine通过数据模型的划分(超级表+数据表)将最小处理粒(表)限定在一个vnode能够处理的范围内,从而避免数据分区。
负载均衡通过dnode汇报心跳到管理节点的方式,由管理节点全局管理负载均衡。
上述的集群管理设计中也有一个重要假设:设备发送数据的频率在秒级别,按照一秒的频率一年的数据是0.5G,如果按照毫秒的话就是500G。
可能存在的问题
以上基本是我关心的tdengine的设计问题,总结下来“可能”有如下问题:
表的数量太多的问题
由于每个序列都是一个单独的表,尤其当一个序列中存在两个收集频率不一致的列的时候,tdengine都必须创建两张表来分别存储这两列;
一方面使用方式上不便利,另一方面如此大量的数据表的元信息存储在内存中,将会导致管理节点内存资源紧张。scheme需要预先定义
普通查询需要在client端进行数据聚合等操作
除此之外,这篇文章浅谈时序数据库TDengine也提到了一些写入和查询上的缺陷。
从上面的“缺点”来看,似乎已经没有必要再纠结于测试报告的详细内容,因为看起来tdengine解决的问题根本不是传统大家认为的时序数据库解决的问题,它做了太多的假定,而这些假定和当前互联网企业使用时序数据库的方式有很多不一致的地方。
感想
经过上述简要分析,我们其实也能大概理解tdengine为何性能如此之好了;
无论是上述“tdengine可能存在的问题”还是后一篇公众号文章说的tdengine的问题,其出发点都是机器监控场景,可是tdengine从一开始就已经说明了“专为物联网而生的大数据平台”,机房的机器监控数据属于“物联网大数据平台”的场景吗?
每个软件产品都有其目标场景,并且针对目标场景进行了特定优化,在做这些优化的同时通常伴随着牺牲其他方面;
具体到测试报告的结果上,与其说是tdengine在测试报告上耍小聪明,不如说,tdengine团队从业务需求上掌握了时序物联场景的核心场景?并且针对这一场景在通用时序数据库/平台的基础上强化了时序物联场景的特定需求?
客户是否买单是检验产品是否成功的唯一标准,我目前持乐观态度,因为传统企业的场景和互联网的机器监控场景确实差别很大,让我们且看tdengine的客户增长情况。