dkron是使用golang写的一个分布式定时任务框架,作者称是因为受到google的Reliable Cron across the Planet的启发写的;
特性:
- 部署简单,一个binary就能启动
- 支持不同类型的后端存储
- 支持metrics
- 有一个前端页面可以显示任务的状态信息
- 有api可以方便的对任务做CRUD
- 支持不同类型的executor
- 支持任务串联(dag)
- 可以进行并发控制
- 支持集群
遇到的问题:
- 前端页面的jobs不支持分页,找起来很麻烦
- api的错误提示不友好,需要不断尝试
- 并发控制只能控制集群中单个点的执行的并发,无法全局控制
- 集群没有保证任务只执行一次,有几个节点就会执行多少次
- 在频繁对任务进行CUD的情况下,调度会miss很多任务的执行,因为其内部在不断的scheduler restart
其中我们主要的使用方式为定期对任务进行调度
- 定时进行模型训练
- 定时进行异常检测
- 支持手动触发模型训练和异常检测:在时间还没有到的时候,人为手工触发训练和检测
在使用的过程中,有用户频繁手工触发训练和检测,导致那个时间段内出现任务无法正常调度的情况,短则十几分钟,长则一个小时,影响线上服务稳定性;

通过读代码,了解了dkron的整体架构
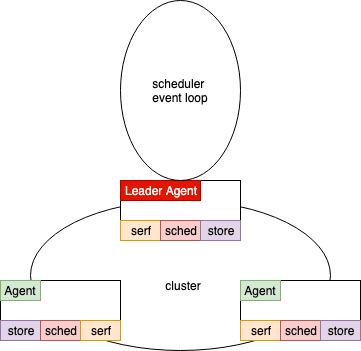
以上是一个dkron架构的简略图,它有如下一些设计要点
- 每个Agent就是一个运行的实例
- 每个Agent大概包括三个组成部分
- store是用来和数据库交互的模块
- serf是用来在实例直接传递消息的,主要是分发定时任务到节点上
- sched是调度器,用来驱动定时任务的执行,一旦时间点到了之后就通过serf发送执行任务的消息到集群中
- 每个Agent可以标记自己是否为server,只有sever才会运行sched调度器,纯agent只被动接收server发过来的广播信息,来执行任务
- 集群的选主是通过etcd的分布式锁实现的
添加任务/修改任务/删除任务的过程
- 首先修改任务到store,落盘
- 重启scheduler;重启过程会全量从store中拉取所有的任务,一次性加载到scheduler内存中
基于以上设计,每次的对任务进行CUD都会造成重启scheduler,当一段时间密集的进行任务的CUD的时候,会造成scheduler一直在重启,没有时间执行任务;
这么设计好处在于可以保证scheduler内存中的数据始终保持和store中的一致,减少管理的复杂度;
打个比喻来说,这种设计方式可以理解为飞机开着的时候不允许上下乘客,必须降落才能上下乘客,我们遇到的问题是乘客不断上下飞机,导致飞机刚起飞就必须降落来拉乘客,所以飞机一直飞不远,为了解决这个问题,我们需要让飞机支持一边飞还可以上下乘客;
具体方式就是在添加任务/修改任务/删除任务的时候一方面修改store中的值,一方面修改scheduler内存中的任务,从而达到目的;
{kind=link}
经过一段时间的运行,可以看到scheduler次数大大减少,再也没有出现过任务无法调度的情况。